A Structured Self-Attentive Sentence Embedding
Introduction
Architecture
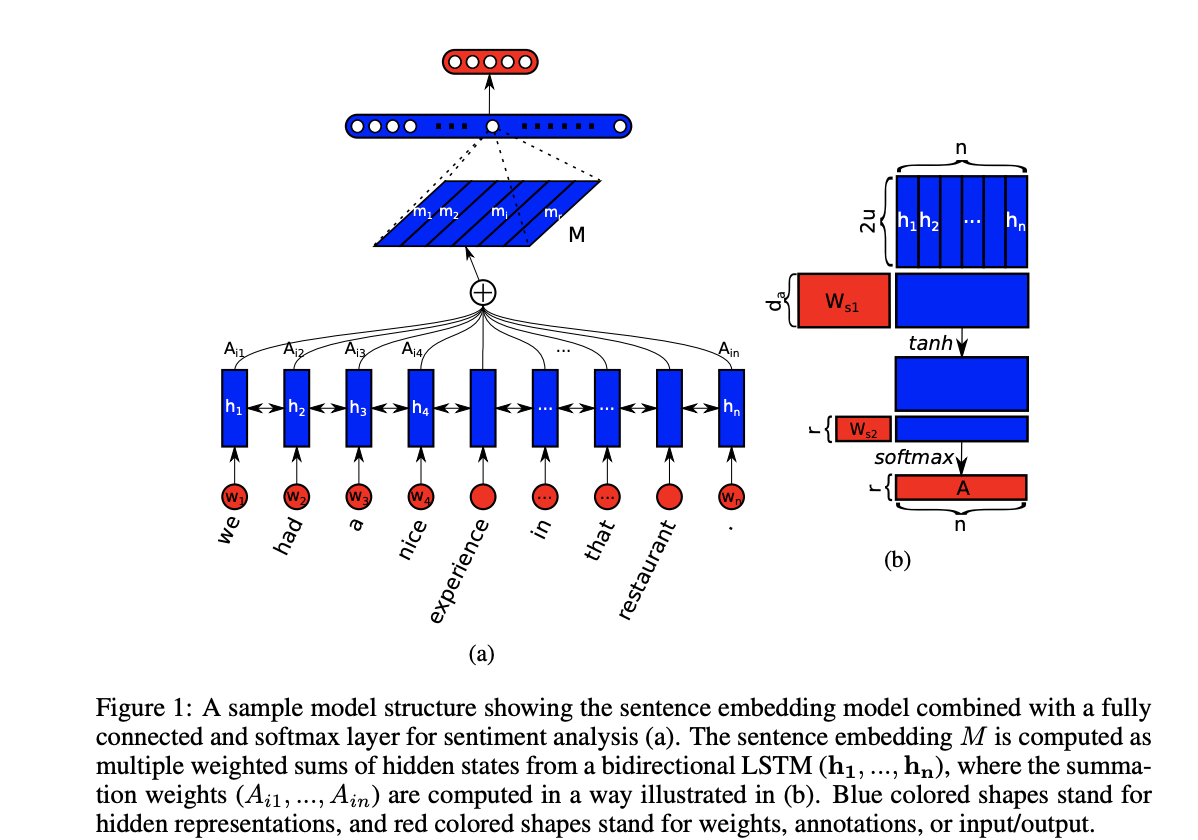
H = hidden states of Bi-LSTM (N*2u) a = softmax(V_s2 * tanh(W_s1 * H^T))
where the dimensionality of a is n.
But we might need multiple such vectors, lets say r and hence we set
A = softmax(W_s2 * tanh(W_s1 * H^T))
where the dimensionality of A is r*n
M = AH (r * 2u)
Results


Kaushik Rangadurai
Code. Learn. Explore