Bigtable: A Distributed Storage System for Structured Data
Bigtable is a distributed storage system for managing structured data. It is used in many projects at Google like Web Indexing, Google Analytics and Google Earth. Here’s the summary of the paper -
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map. They key of the map is a tuple of (RowKey, ColumnKey, Timestamp) and the value is a byte array. Let’s look at them in detail -
Rows, Column Families and Timestamp
Bigtable maintains the data sorted by the row key. Consider the example of a Webtable, where the row key is the URL of the web-page. In order to make sure that all the web-pages of a domain are stored together, one can store the URL by reversing the hostname. For example, maps.google.com/index.html becomes com.google.maps/index.html. This would make sure that all the web-pages starting with com.google would be stored together. The entire table is partitioned by a range of rows known as the tablet.
Column keys are grouped into sets known as Column Families. A column key is named using the following syntax -> family:qualifier. An example column family for the Webtable is an anchor. Each column key in the family represents a single anchor and the qualifier is the name of the referring site. A column family has the following properties -
- All the columns in a column family usually have the same type.
- A column family is the smallest unit for access controls.
- A column family must be created before any data could be stored in any of the columns.
Each web-page in a WebTable contains multiple versions of the web-page and these versions are stored using the timestamp (64-bit integers representing the time in microseconds). To make it easy to maintain different versions of a web-page, Bigtable supports 2 types of garbage collection (throwing out old web-pages) - M most recent web-pages and also all versions of web-pages in the last N days.

Dependency to Other Google Infrastructure
BigTable is built on several other infrastructure components of Google. For example, all the logs are stored in Google File system (GFS). In this section , we’ll look at 2 key components - SSTable and Chubby.
An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are byte strings. SSTable supports operations for look up based on a key or a range of keys (specified key range).
Chubby is a highly-available and persistent lock service. Chubby provides a namespace that consists of directories and files. Each directory of a file can be used as a lock. Reads and writes to a file are atomic. Bigtable uses Chubby for many purposes - for storing bootstrap location of Bigtable data, to discover tablet servers, to store Bigtable schema and a few other use cases.
Tablets
The Bigtable implementation has 3 major components - a client libaray, one master server and several tablet servers. Each tablet server manages a set of tablets - it handles the read and write requests to the tablets and also splits tablets that have grown too large. The master is responsible for assigning tablets to tablet servers, adding, removing and detecting the failure of tablet servers, tablet-server load balancing and garbage collection of files in GFS.
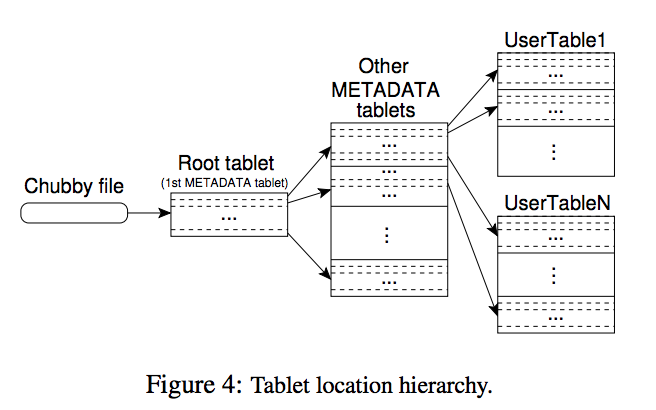
Locating a Tablet
- The client first looks for the tablet location in its cache.
- If the cache is a miss, it then it moves up the tablet hierarchy. At the top of the hierarchy is a Chubby file.
- The Chubby file has the location of the root tablet. The root tablet is the first first tablet in the METADATA table (a table of row key to location).
- When the first METADATA tablet is loaded, it then has pointers to other METADATA tablets which eventually point to User tablets (data) in the third layer.
Assigning a Tablet - This is a sequence of steps that occur when a master is started in a cluster -
- The master grabs a unique master lock in Chubby. Similarly, each tablet server will acquire a lock on a uniquely-named file in a specific directory. This is how the master keeps track of the Tablet Servers.
- The Master scans this directory in Chubby to find the live servers.
- The master communicates with each tablet server to discover which tablets are assigned to which servers.
- The master scans the METADATA table to learn the location of the tablets.
- If a tablet server loses the lock on a file, then it kills itself. It also adds the tablets that it had owned to the unassigned tablets (for them to be assigned to a tablet server by the Master).
Reading and Writing a Tablet
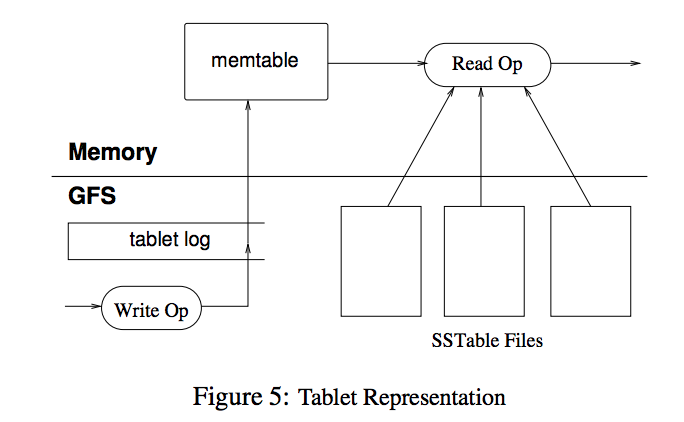
When a write operation comes to the Tablet Server, it first checks if it is well-formed. If the mutation is valid, then a write is performed to a commit log. After the write has been committed, it is inserted to a memtable.
When a read operation comes to the Tablet Server, it again checks if it is well-formed. The read operation is executed on an abstracted merged view of the sequence of SSTables and the memtable.
The paper then discusses some refinements and you can read about it here.

Kaushik Rangadurai
Code. Learn. Explore