Deep Neural Networks for YouTube Recommendations
This paper discusses how YouTube uses Deep Learning for their home page recommendations. This paper gives a good understanding on how to build a deep learning product. You can read the paper here.

Architecture
The overall structure of the recommendation system consists of 2 neural networks - one for candidate generation and one for ranking. Candidate generation takes millions of videos and returns hundreds of potential candidates to rank. As a result, the candidate generation has to be lightweight and the model doesn’t need to output exact scores. The candidate generation network only provides broad personalization via collaborative filtering where the similarity between the users is used. The ranking network needs to have a fine-level representation to distinguish relative importance among candidates with high recall. It uses a rich set of features (user and video) trying to optimize a desired objective function (more on this later).
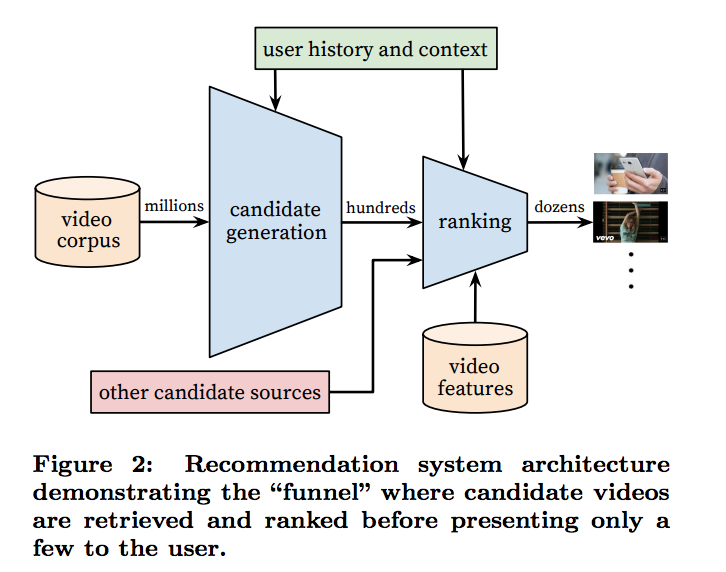
Candidate Generation
In Candidate Generation, recommendation is posed as an extreme multiclass classification problem (does the user like a video vi or not). The task of the neural network is to learn the user embeddings u as a function of user’s history and context that are useful for discriminating among videos with a softmax classifier. The Candidate Generation network uses approximate nearest neighbor search methods in the dot product space to return the top videos.
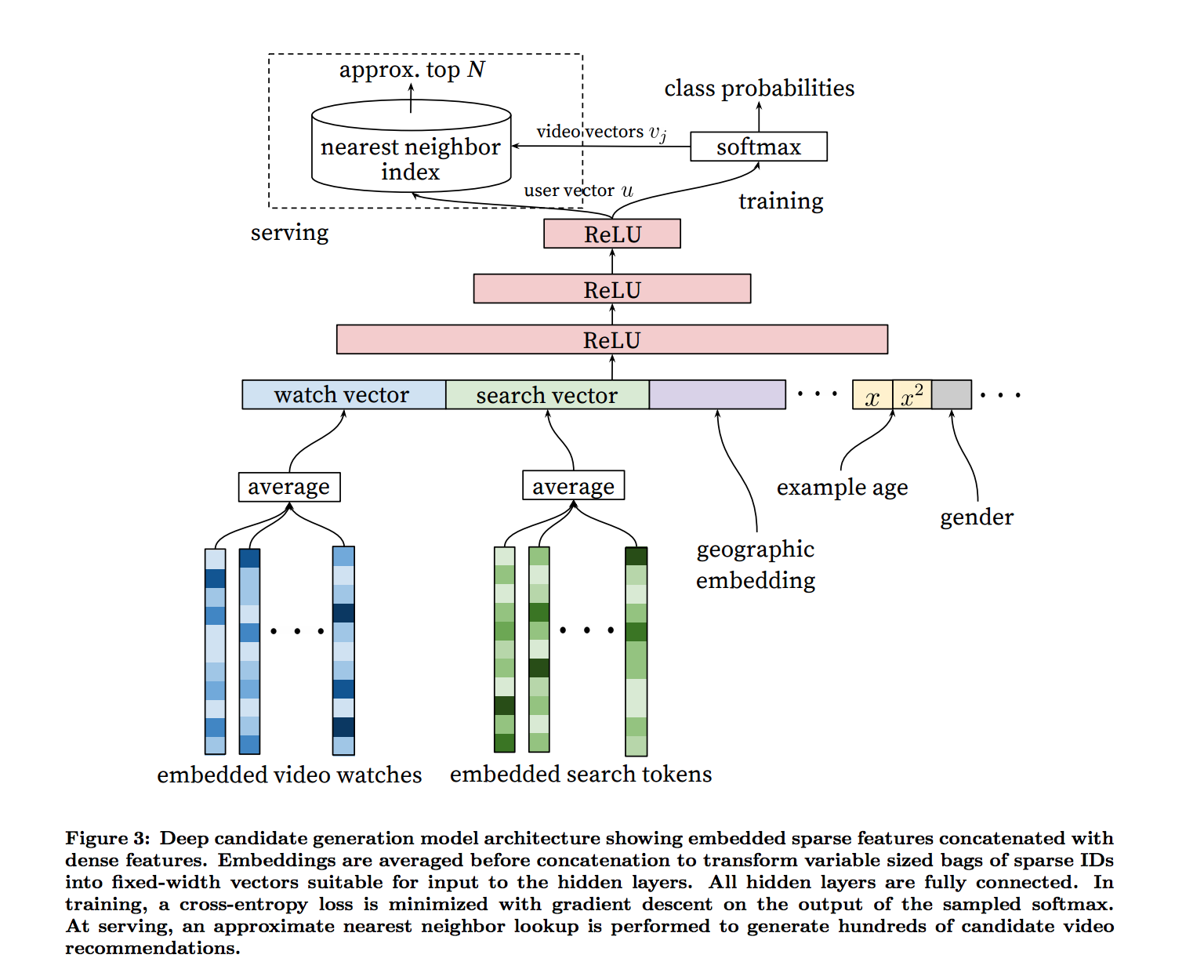
The model learns the high dimensional embeddings using the continuous bag of words model. A user’s watch history embedding is formed using averaging the each video’s embedding although other aggregation methods like sum, component wise max were tried. The features are concatenated and fed into the wide first layer of the network followed by several layers of fully connected ReLU.
Training examples are generated from all YouTube videos and not just from the Recommender system (avoids bias towards the original model). Another trick that helped in improving the live metrics was to weighting the users equally in the loss function to prevent a small cohort of active users from dominating the loss. In prediction, the data is separated in such a way as to predict the Next watch (based on timestamp) rather than a random Held-out watch.
An important feature in this model that is discussed in the paper is the Age feature. Most of the machine learning systems exhibit a bias towards the past. As a result, there is an implicit bias towards the popular and older videos. To correct for this bias, the age of the training example is used as a feature. At serving time, this feature is set ot zero.
Ranking
The ranking network has access to many more features describing the video and the user’s relationship to the video because only a few hundred videos are being scored. Ranking is also used as there could be multiple candidate generation sources (not just the one described above).
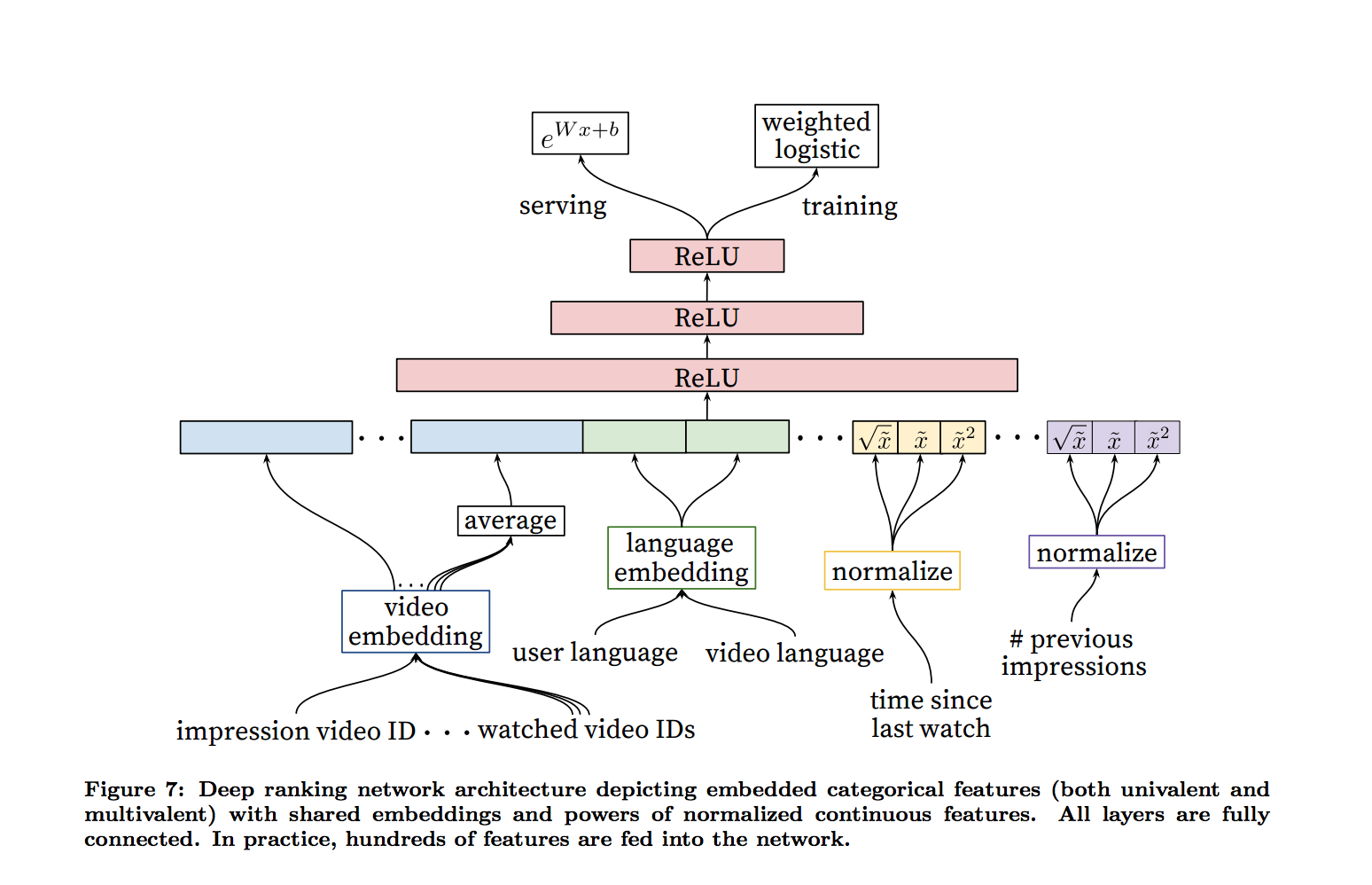
As described in the diagram above, categorical features are embedded and continuous features are normalized. Some of the features are propagated from the candidate generation network to the ranking network e.g. which sources nominated this video candidate and what is their score. However, the most important signals in the ranking network are those that describe a user’s previous interaction with the item or similar items. Also, features describing the frequency of past video impressions are critical in ensuring that the successive requests to the recommendation system do not return identical lists. Weighted logistic regression optimizing the cross entropy loss is used in the output layer where the weight is equal to the observed watch time on the video.

Kaushik Rangadurai
Code. Learn. Explore