Hierarchical Attention Networks
Overview
- Not all parts of a document are equally important to determine the class.
- Words form sentences, sentences form document.
- The importance of words or sentences are context dependent.
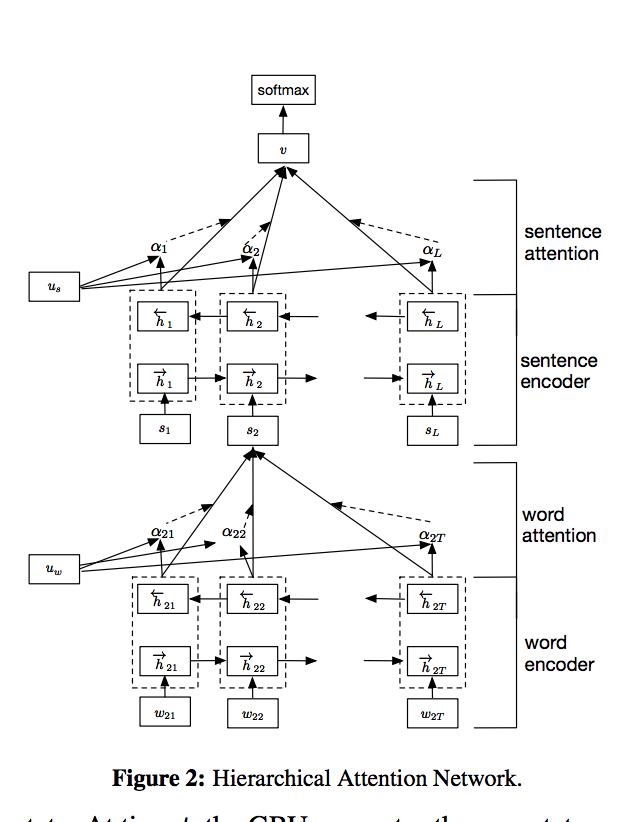
Architecture
GRU
A quick refresher on GRU’s here -
\[\begin{align*} h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \end{align*}\]From the above equation, the hidden representation of a time-step is a linear interpolation of the previous state and the current new state based on the value of the update gate. The value of the update gate is calculated based on this -
\[\begin{align*} z_t = \sigma{(W_zx_t + U_zh_{t-1} + b_z)} \end{align*}\]The current state is a mix of the input and the previous state and the proportion is decided by the rest gate -
\[\begin{align*} \tilde{h}_t = tanh(W_hx_t + r_t \odot (U_hh_{t-1})+ b_h) \end{align*}\]And the value of the rest gate is calculated similar to the update gate (all the weight matrices are learned) -
Word Attention
We concatenate the forward and backward hidden states to get the representation of every token. Now, in order to calculate the sentence level representation, instead of taking the final hidden state, we compute a weighted average of the hidden states based on attention mechanism. We do this in 3 steps -
Project the hidden state onto a smaller dimension -
\[\begin{align*} u_{it} = tanh(W_wh_{it} + b_w) \end{align*}\]Next, we compute the attention for each of the time-step based on similarity to the context vector.
\[\begin{align*} \alpha_{it} = exp(u_{it} u_w) / \sum_{t} exp(u_{it} u_w) \end{align*}\]Now, we get a representation of the sentence by doing a weighted average -
Sentence Attention
The sentence attention is calculated in a very similar way to form a vector representation of a document. This representation is then followed by a dense layer and then a softmax to do the classification.
Results
| Paper | Yelp’13 | Yelp’14 | Yelp’15 | IMDB | Yahoo Answers | Amazon |
|---|---|---|---|---|---|---|
| Tang et al. 2015 LSTM-GRNN | 65.1 | 67.1 | 67.6 | 45.3 | - | - |
| HN-ATT | 68.2 | 70.5 | 71.0 | 49.4 | 75.8 | 63.6 |

Kaushik Rangadurai
Code. Learn. Explore