BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Overview
- BERT stands for Bidirectional Encoder Representation from Transformer
- Jointly conditioning on both the left and right context in all layers.
- Pre-trained BERT can be fine-tuned by adding 1 additional layer for a bunch of NLP tasks.
- Two strategies for applying pre-trained language representations -
- Feature Based (ElMo): Task specific architectures that uses the embeddings as additional features.
- Fine-tuning (GPT) - Simply fine-tuning the parameters with minimal architecture change.
Architecture
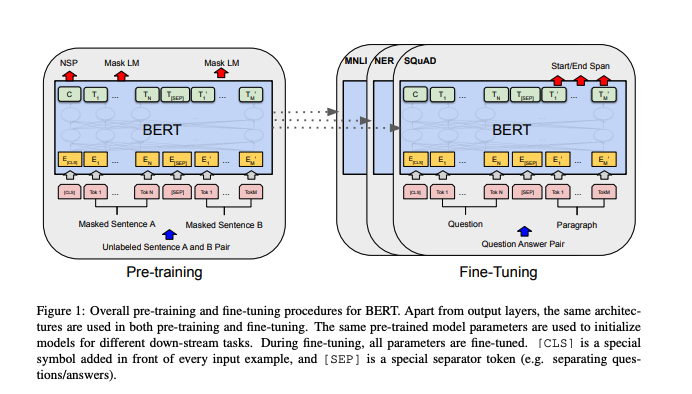
- Unified architecture across different tasks.
- Multi-layer bidirectional Transformer encoder based on Vaswani et al.
- BERTBASE = (L=12, H=786, A=12, P=110M)
- BERTLARGE = (L=24, H=1024, A=16, P=340M)
Input/Output Representation
- Represent both a ‘sentence’ and a ‘pair of sentence’ in 1 sequence.
- The first token of every sequence is always a [CLS] - this token represents the entire information of the sequence.
- Have a [SEP] token between the 2 sentences. Also, add a learned embedding to every token where it belongs to sentence A or sentence B.
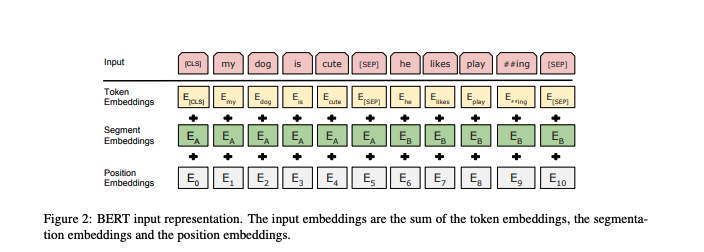
- The representation of an input is the sum of the embedding of the input along with the segment and position embeddings (as shown in figure below).
Masked LM
- Unfortunately, standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional conditioning would allow each word to indirectly “see itself”, and the model could trivially predict the target word in a multi-layered context.
- In MLM, we mask some tokens (replace with [MASK]) in a sequence and then predict those tokens.
- Mask 15% of the tokens randomly.
- 80% convert to [MASK], 10% random replace and 10% exact replace.
- Just like in LM, we pass the final hidden vectors of these masked tokens to a softmax and predict over the vocabulary.
Next Sentence Prediction
- When choosing sentences A and B, 50% of the time B is the next sentence and 50% of the time it is not.
- C predicts whether or not it is the next sentence.
Data
- Wikipedia and BookCorpus.
Results
| Paper | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|---|---|---|---|---|---|---|---|---|---|
| BERT Large | 86.7/85.9 | 72.1 | 92.7 | 94.9 | 60.5 | 86.5 | 89.3 | 70.1 | 82.1 |
| OpenAI GPT | 82.1/81.4 | 70.3 | 87.4 | 91.3 | 45.4 | 80.0 | 82.3 | 56.0 | 75.1 |

Kaushik Rangadurai
Code. Learn. Explore