HDBScan
Overview
- Clustering at it’s heart is about grouping data points that are very similar.
- Clustering is naturally centroid based (assume shape) or density based (data to define shape).
- Hierarchical Density Based Spatial Clustering for Applications with Noise (HDBSCAN).
Architecture
There are 5 steps involved in HDBScan.
1.Transform The Space
- The goal of this stage is to separate the noise from the data (the sea from the land).
- This doesn’t have to be perfect - just the initial stage.
- We need an inexpensive metric of density - something that is local and quick to compute - distance to kth nearest neighbor.
- This pushes the sparse points further away and also has the nice triangular property.
2. Build Minimum Spanning Tree
- Minimum Spanning Tree is the minimum distance to traverse all the nodes in the tree.
- We build the tree one edge at a time, always adding the lowest weight edge that connects the current tree to a vertex not yet in the tree.
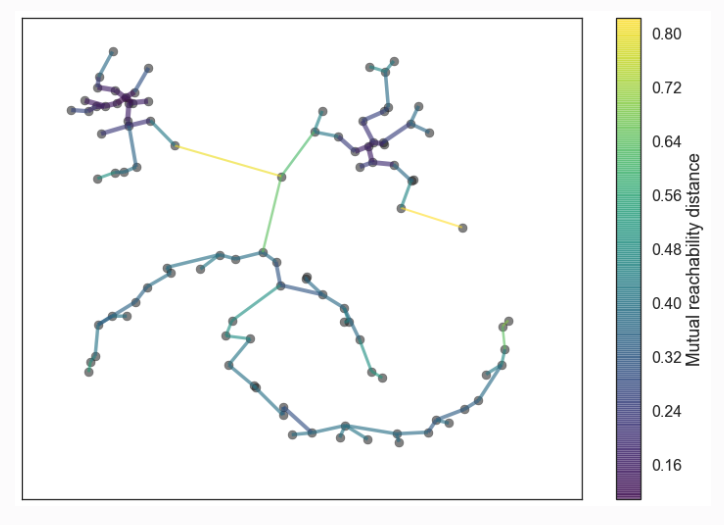
3. Build Cluster Hierarchy
- The goal is to convert the minimum spanning into cluster of connected components.
- Sort the edges of the tree by distance (in increasing order) and then iterate through, creating a new merged cluster for each edge.
- In DBScan, unintuitive parameter called epsilon (radius) - larger epsilon, single cluster.
- For very small epsilons, we’re guaranteed to find the density cluster tree.
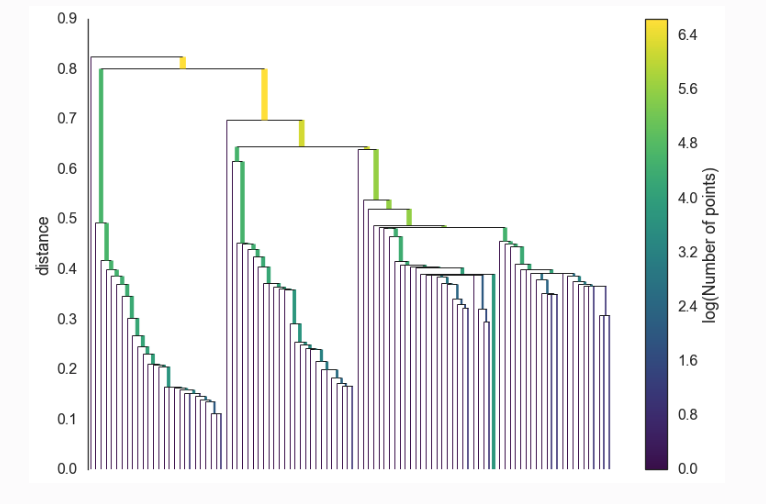
4. Condense Cluster Tree
- At each split ask if one of the new clusters created by the split has fewer points than the minimum cluster size.
- If it is the case that we have fewer points than the minimum cluster size we declare it to be ‘points falling out of a cluster’ and have the larger cluster retain the cluster identity of the parent, marking down which points ‘fell out of the cluster’ and at what distance value that happened.
- If on the other hand the split is into two clusters each at least as large as the minimum cluster size then we consider that a true cluster split and let that split persist in the tree.

5. Extract The Clusters
- Intuitively the goal is to pick the clusters with maximum area and if we pick a cluster, we can’t pick the children.
- First we define a lambda measure which is the inverse of the distance. We define this measure at birth (when the cluster was formed) and at death (if any).
- Stability of the cluster is the sum of the stability of individual points in the cluster.
References

Kaushik Rangadurai
Code. Learn. Explore