Conversational Recommender System
Introduction
- Unified deep reinforcement learning framework to build a personalized conversational recommendation agent that optimizes a per session based utility function.
- Represent a user conversation history as a semi-structured user query with facet-value pairs.
- Propose a set of machine actions tailored for recommendation agents and train a deep policy network to decide which action (i.e. asking for the value of a facet or making a recommendation) the agent should take at each step.
- Train a personalized recommendation model that uses both the user’s past ratings and user query collected in the current conversational session when making rating predictions and generating recommendations.
- Collect user preferences by asking questions. Once enough user preference is collected, it makes personalized recommendations to the user.
3 Main Modules -
- NLU - alyzing each user utterance, keeping track of the user’s dialogue history and constantly updating the user’s intention.
- Dialog Management (DM) - decides which action to take given the current state.
- NLG - Generate response to the user.
The lines of research in this paper is an intersection of Dialogue Systems (DS), Recommender Systems, Faceted Search and Reinforcement Learning (RL).
Architecture
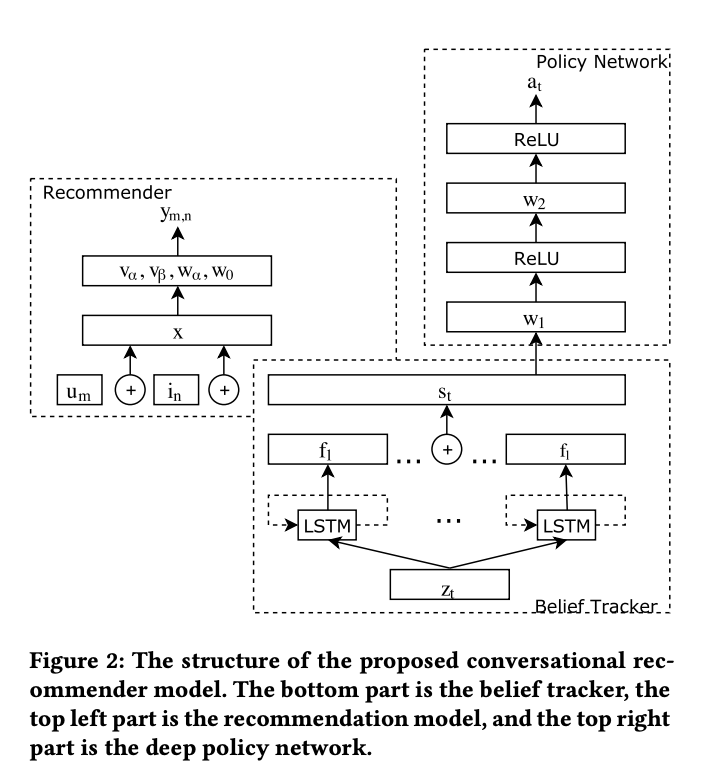
Belief Tracker
-
We view the product facet (or attribute, metadata) f along with its specific value v as a facet-value pair (f ,v). Each facet-value pair represents a constraint on the items. For example, (color,red) is a facet-value pair which constrains that the items need to be red in color.
-
For each facet f, we pass the user utterance through an LSTM network and then feedforward and softmax.
-
We concatenate all f to form the final state representation s_t.
Recommender System
- Use Factorization Machines (FM) for the reason that FM can combine different features, e.g. st, together to train the recommendation model.
- Concatenate user vector, item vector and state representation (s_t) to predict whether the user will like the item based on current state.
Reinforcement Learning


Kaushik Rangadurai
Code. Learn. Explore