Deep Averaging Networks
Overview
- Simple Neural Network that learns the compositionality of the inputs.
- The model is syntactically ignorant but competes and outperforms expensive models.
- Makes similar errors to syntactically-aware models.
Composition Functions
Functions applied to word embeddings to get sentence embeddings. They’re of 2 types -
- Unorderded - bag of words like (sum, average etc)
- average outperforms sum (preliminary results)
- Syntactic - takes order of words into consideration (RecRNN)
- Recursive Neural Networks are syntactic functions that learn the inherent structure of natural language.
- The composition function g now depends on the parse tree of the input sequence.
- More training time
- Needs more label.
Architecture
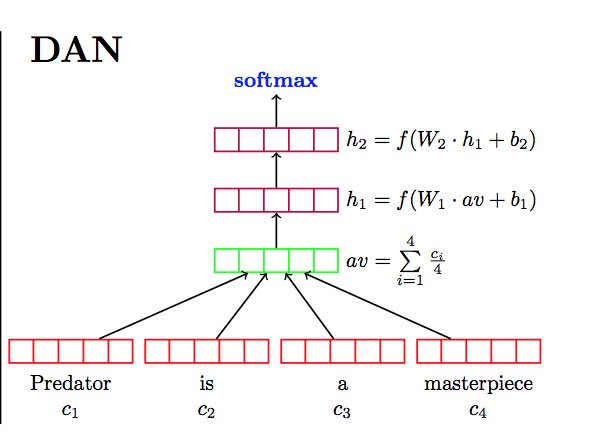
Deep Averaging Network (DAN) -
- Take the vector average of the input embeddings.
- Pass it through 1 or more feed-forward layers
- Intuition being that each layer will increasingly magnify small but meaningful differences in the word embedding average.
- Perform Linear classification on final layer.
Word Dropout
- Instead of dropping units, we drop word tokens.
- Network theoretically sees 2^X different token sequences.
- Improves model accuracy.
Results
| Paper | RT | SST | IMDB |
|---|---|---|---|
| DAN | 80.3 | 86.3 | 89.4 |
| NBOW | 79 | 83.6 | 89 |
| PVec | - | 87.8 | 92.6 |
Observations
- 0.3 dropout rate worked the best
- 2-3 layer-depth is best for DAN. But any depth is better than no-depth.
- Perturbation Analysis - As a DAN gets deeper, the differences between negative and positive sentences become increasingly amplified.
- DANs performed comparably well on “negations” or “contrastive conjunctions” but not able to capture double negations (movie was not bad).

Kaushik Rangadurai
Code. Learn. Explore