Attention is All You Need
Overview
- Traditional Seq2Seq models use Gated RNN (GRU, LSTM etc) and attention mechanisms on top of that.
- This makes training sequential and significantly slows training time.
- Attention mechanisms have been an integral part of compelling sequence modeling.
- Why not directly use attention? Do we really need RNNs?
Architecture
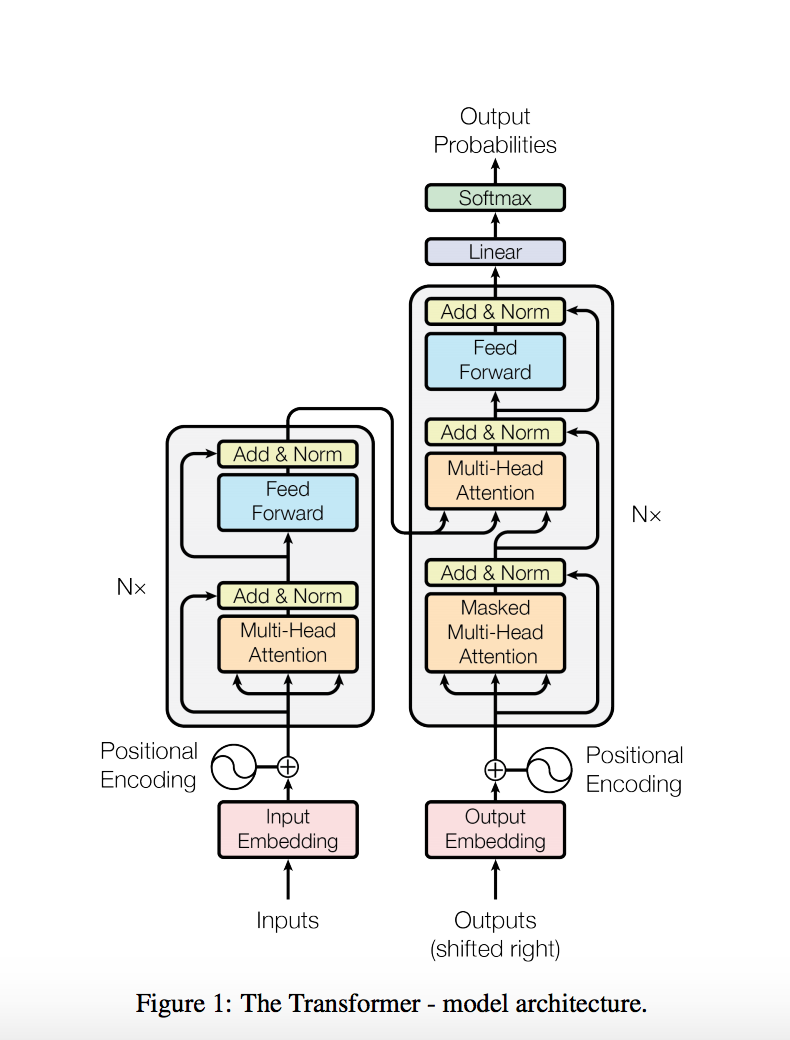
- Standard Encoder Decoder architecture trained on Machine Translation (WMT English-German).
- Encoder converts (x1,… xn) to a continuous representation z (z1,… zn).
- Given z, decoder then generates an output sequence (y1,… ym) one token at a time.
- At each step, the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
Scaled Dot-Product Attention
Compute the attention between Queries and Keys (each of dimension dk) and use it to find the weighted sum of values (dimension dv).
\[\begin{align*} Attention(Q, K, V) = softmax(\dfrac{QK^T}{\sqrt{d_k}})V \end{align*}\]- Dot Product much faster to compute than Additive attention
- For larger values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it as extremely small gradients. To counteract this effect, we scale the dot products.
Multi-Head Attention
- Beneficial to linearly project the queries, keys and values h times with different learned linear projections.
- We perform attention on these projections yielding dv-dimensional output values.
- These are concatenated once again to get the output.
- In the model, h = 8 (8-headed attention).
- This allows the model to jointly attend to information from different representation spaces.
Attentions Used In This Paper
- Encoder/Decoder Attention : Queries come from the previous decoder layer and the memory keys and values come from the Encoder. Standard Encoder/Decoder Attention.
- Self Attention in Encoder - all 3 (Q, K, V) come from the previous encoder layer.
- Self Attention in Decoder - Same as above but we need to prevent leftward information flow (auto-regressive property). This is implemented through masking.
Position-wise Feed-Forward Networks
- Each of the layers in the encoder and decoder contains a FFN. This consists of 2 linear transformations with a ReLU in-between.
Positional Encoding
- Use sin and cos to learn positional embeddings (to counteract the lack of LSTMs).
Miscellaneous Things
- Residual Dropout
- Pdrop is 0.1
- Apply dropout to the output of each sub-layer before it is added to the input of the layer and normalized.
- Label Smoothing
- HyperParam is 0.1
- Hurts perplexity but improves accuracy and BLEU score.
Results
| Paper | EN-DE | EN-FR |
|---|---|---|
| MoE | 26.03 | 40.56 |
| Transformer Base | 27.3 | 38.1 |
| Transformer | 28.4 | 41.0 |
References
- http://nlp.seas.harvard.edu/2018/04/03/attention.html

Kaushik Rangadurai
Code. Learn. Explore