Blockwise Parallel Decoding for Deep Autoregressive Models
Overview
- Autoregressive Seq2Seq models are de-facto used for machine translation, summarization and speech synthesis.
- The generation of text in deep autoregressive models still remains an inherently sequential process.
- Parallel Blockwise decoding scheme - make predictions for multiple time steps in parallel and back-off to longest prefix validated by a scoring model.
- Core concept - make multiple predictions and then 1 validation step by the base model.
Architecture
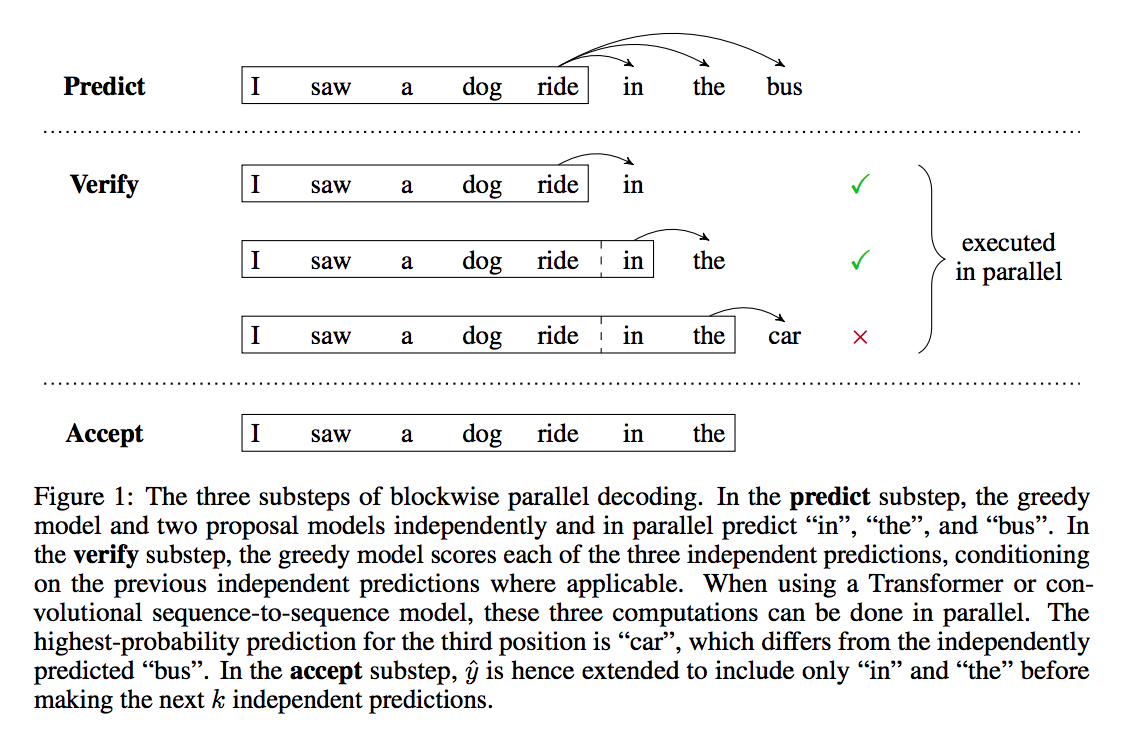
Blockwise Parallel Decoding
- Predict - Get the block predictions for the next k steps.
- Verify - Find the largest prefix of k (say m) that is valid according to the base language model.
- Accept - Extend y to yj+1 and now set j = j + m
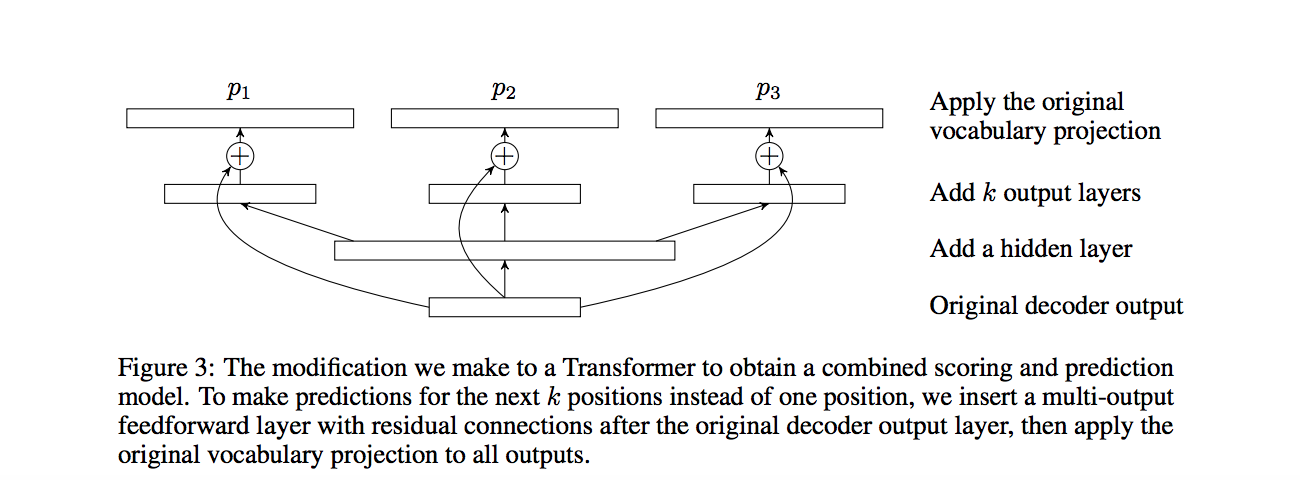
Combined Scoring and Proposal Model
- Based on the above architecture, we would reduce from m steps to 2m/k steps (m/k for predict and m/k for verify).
- However, this can further be reduced to m/k + 1 - if we assume a combined scoring and proposal model, in which case the nth verification step can be merged with the (n+1)th prediction substep.
- This can be achieved by, for example, having k separate softmaxes (1 per per position).
Other Details
- TopK-Selection - as long as the token predicted is in the TopK during verification.
- Distance-Based Selection - distance between tokens (makes sense for images).
Results
| Paper | BLEU |
|---|---|
| Transformer (beam size 4) | 28.4 |
| Blockwise parallel decoding (k=4) | 28.54 |
| Transformer with distillation (k=1 | 29.11 |

Kaushik Rangadurai
Code. Learn. Explore