Effective Incorporation of Speaker Information in Utterance Encoding in Dialog
Overview
- Knowing who produced which utterance is essential to understanding a dialog
- Conventional methods tried integrating speaker labels into utterance vectors.
- A relative speaker modeling method is proposed to address the problem and is more useful in SwDA corpus as there are many speakers (not just 2).
Architecture
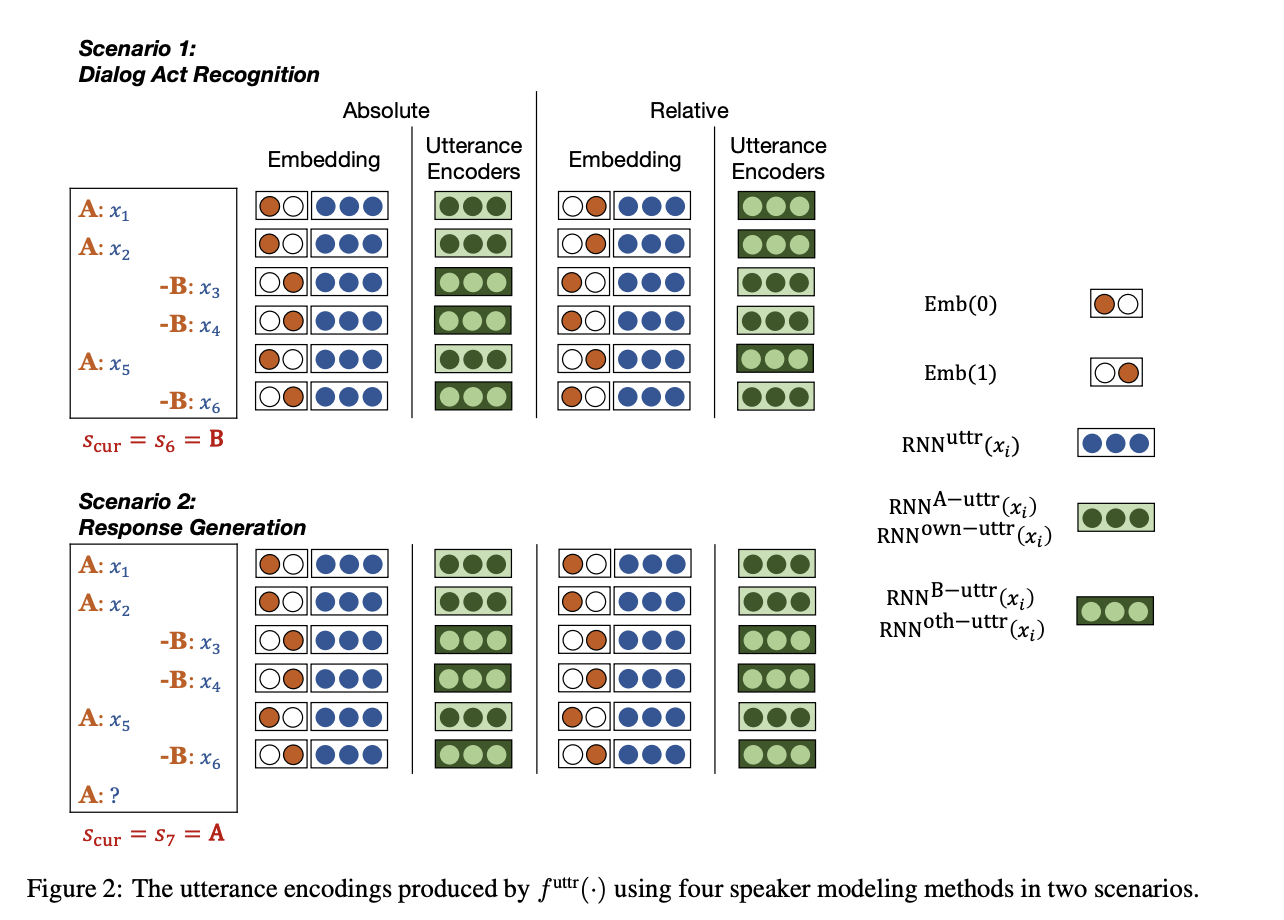
Absolute Speaker Embedding
- Simplest idea is to use 1-hot vectors for Speakers. If there are 2 speakers [1, 0] for speaker A and [0, 1] for Speaker B.
- Another alternate here is to use 2 different encoders (1 RNN encoder for speaker A and 1 for speaker B).
Relative Speaker Embedding
- Have current user and other user. Rest all stuffs flows naturally as above.
Results
| Model | Accuracy |
|---|---|
| Baseline | 79.0 |
| Absolute | 78.9 |
| Relative | 80.17 |

Kaushik Rangadurai
Code. Learn. Explore