Gmail Smart Compose: Real-Time Assisted Writing
Overview
- A system for providing real-time, interactive suggestions to help users compose messages quickly and with confidence in Gmail.
- Challenges include latency (90th percentile is 60 ms (<100ms)), scale (1.5 billion users), personalization, fairness and privacy and Metrics Design (offline metrics correlate with online).
Architecture
Data
- Previous E-Mail
- Subject
- Date & time (discrete)
- Locale
Preprocessing
- Language Detection (strip text not in language)
- Segmentation & Tokenization - sentence boundaries detected, sentences are broken down into words and punctuation marks.
- Normalization - Infrequent words and entities like name, email, URL and phone numbers are replaced by special tokens.
- Quotation Removal - quoted original message is removed.
- Salutation/Close Removal
Models
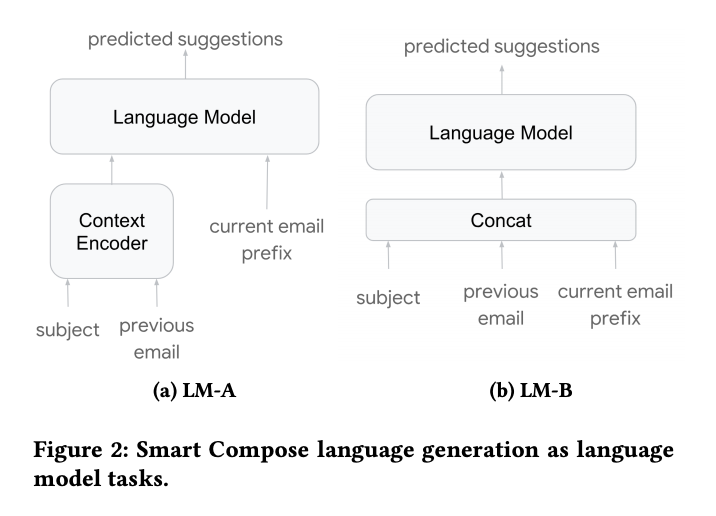
- In LM-A: Input sequence (to LM) is the prefix of the current e-mail. The context is encoded using a dedicated encoder (average word-embeddings) and is concatenated at each time step of the LM.
- In LM-B: Input sequence is concatenation of (subject, previous email, current e-mail) with some special token to delimit them. Much simpler but longer sequence.
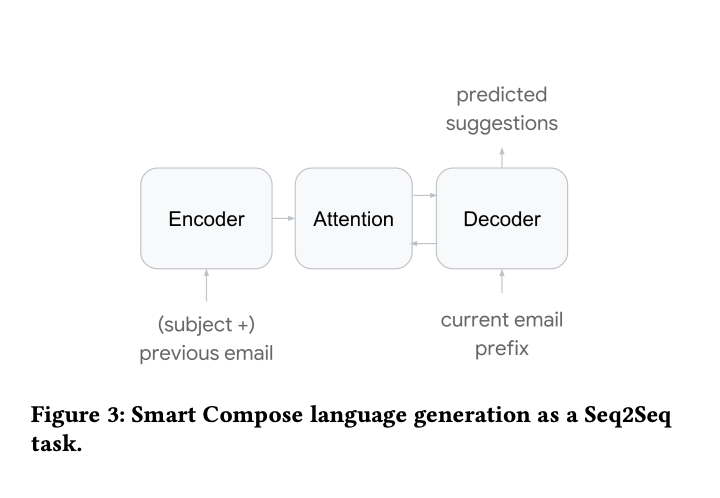
- In Seq2Seq Model: The encoder is subject and previous email body and the decoder is current email body.
Triggering
- Generate n-best predictions/candidates using beam search.
- Each candidate sequence is considered complete when a sentence punctuation token or a special end-of-sequence (
) token is generated, or when the candidate reaches a predefined maximum output sequence length. - Length-normalized log conditional probability as the confidence score of each suggestion sequence and define a triggering threshold based on a target triggering frequency/coverage.
Eval
- Log Perplexity
- ExactMatch@N - In this paper, we report an averaged ExactMatch number by weighted averaging the ExactMatch for all the lengths up to 15.
Production System
- Context Encoding - Cached and stored only once.
- Prefix Encoding - Takes hidden layer and current text. User is assigned to a fixed server, so directly proportional to text typed since last request.
- Beam Search - Takes in various parameters to control beam search (number of steps, valid tokens to end consideration of a beam, and blacklisted words). We can also filter for partial match.
Personalization
- Train for each user a light-weight language model adapted to the user’s personal mail data.
- n-gram language model with Katz-backoff stored using compact weighted finite automata (WFA) format.
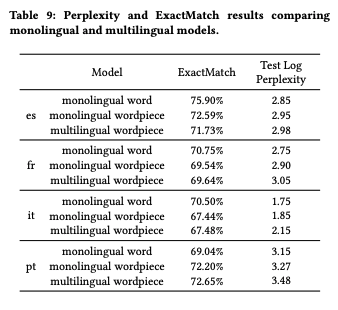
Multi-lingual Model
- Using multilingual wordpiece for ease of maintenance.
Results
RNN Layers
- Use LSTM and residual connections between consecutive layers.
- Adam Optimizer
- Uniform Label Smoothing
Transformer
- Same as Vaswani et al
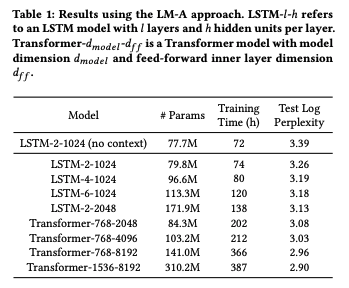
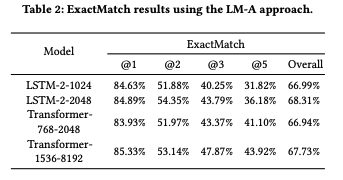
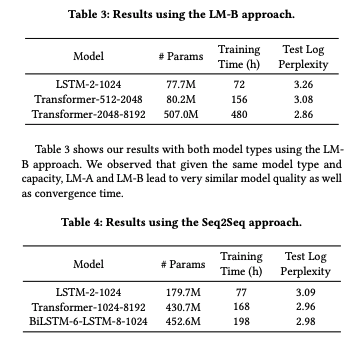
- We observed that for the LSTM-2-1024, simply by joining the averaged embeddings from subject and previous e-mail to the model input reduces the test log perplexity by 0.13, showing that contextual information indeed helps improving model quality.
- We can see that the LSTM seq2seq model outperforms the LSTM language models with similar number of model params, indicating that an encoder-decoder architecture with attention is more effective in modeling the context information.
Future Work
- Adapted version of the Transformer model where self-attention is applied locally over a fixedsized window of steps during decoding, instead of over all previous decoding steps
- Pretrained language models.
- Use VAE.

Kaushik Rangadurai
Code. Learn. Explore