Named Entity Recognition with Bidirectional LSTM-CNNs
Overview
- The core idea from this paper (looking back) is the use of Lexicons.
Architecture
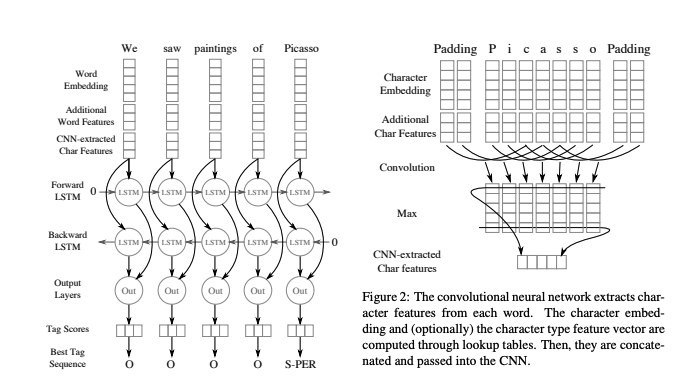
The architecture is very straight-forward (from above diagram). Append word embeddings, word feature and character embeddings from CNN. Pass this through LSTM and have a softmax for every token.
- For each lexicon category, we match every n-gram (up to the length of the longest lexicon entry) against entries in the lexicon.
- A match is successful when the n-gram matches the prefix or suffix of an entry and is at least half the length of the entry. (Discard matches with <= 2 words).
- Prefer exact matches over partial matches, and then longer matches over shorter matches, and finally earlier matches in the sentence over later matches.
- All matches are case insensitive.

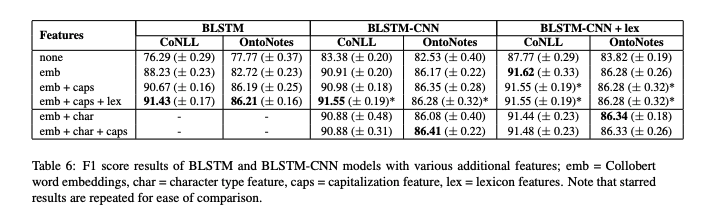
Results

Kaushik Rangadurai
Code. Learn. Explore