Sentencepiece
Introduction
- Language-independent subword tokenizer and detokenizer designed for Neural-based text processing.
- Moses is a de-facto standard toolkit for SMT, implements a reasonably useful pre- and postprocessor.
- SentencePiece implements two subword segmentation algorithms, BPE and unigram language model, with the extension of direct training from raw sentences.
Architecture
Four main components -
Normalizer
- normalize semantically equivalent Unicode characters into canonical forms.
- Mostly includes converting whitespace to u2581.
- The goal is to remain lossless
Trainer
- trains the subword segmentation model from the normalized corpus.
- Similar to BPE but some speed-up is done here from O(N^2) to O(NlogN) by using a heap or priority queue.
- Vocabulary text - The param to tune is vocab_size and not some number of merge operations.
- Customizable character normalization - Can provide a tsv file where a sequence of tokens in first column is converted to the token in second column.
- Self-Contained - the model file is self-contained. Its all you need to encode and decode.
Encoder
- executes Normalizer to normalize the input text and tokenizes it into a subword sequence with the subword model trained by Trainer.
Decoder
- converts the subword sequence into the normalized text.
Lossless Tokenization
- Decode(Encode(Normalize(text))) = Normalize(text).
- Treat the input text just as a sequence of Unicode characters.
- Even whitespace is handled as a normal symbol (U+2581)
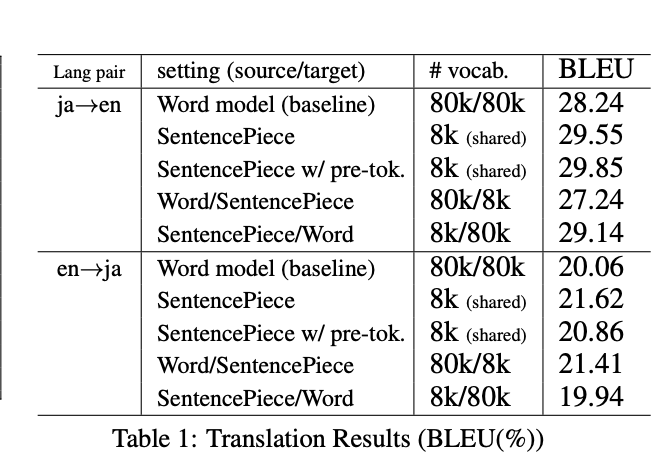
Results

Kaushik Rangadurai
Code. Learn. Explore