Corpora Generation for Grammatical Error Correction
Introduction
- GEC has been recently modeled using the sequence-to-sequence framework but suffers from the lack of plentiful parallel data.
- Two methods proposed here to generate large parallel corpora -
- source-target pairs from Wikipedia edit histories with minimal filtration heuristics.
- second method introduces noise into Wikipedia sentences via round-trip translation through bridge languages.
- Fine-tuning these models on the Lang-8 corpus and ensembling allows us to surpass the state of the art on both the CoNLL2014 benchmark and the JFLEG task.
Architecture
- Transformer sequence-to-sequence model (Vaswani et al., 2017) on data generated from the two schemes.
- Fine-tuning the models on the Lang-8 corpus gives us additional improvements which allow a single model to surpass the state-of-art on both the CoNLL-2014 and the JFLEG tasks.
Wikipedia Revision Histories
- Discard pages larger than 64Mb.
- Selecting only log1.5(n) pairs for a page with a total of n revisions.
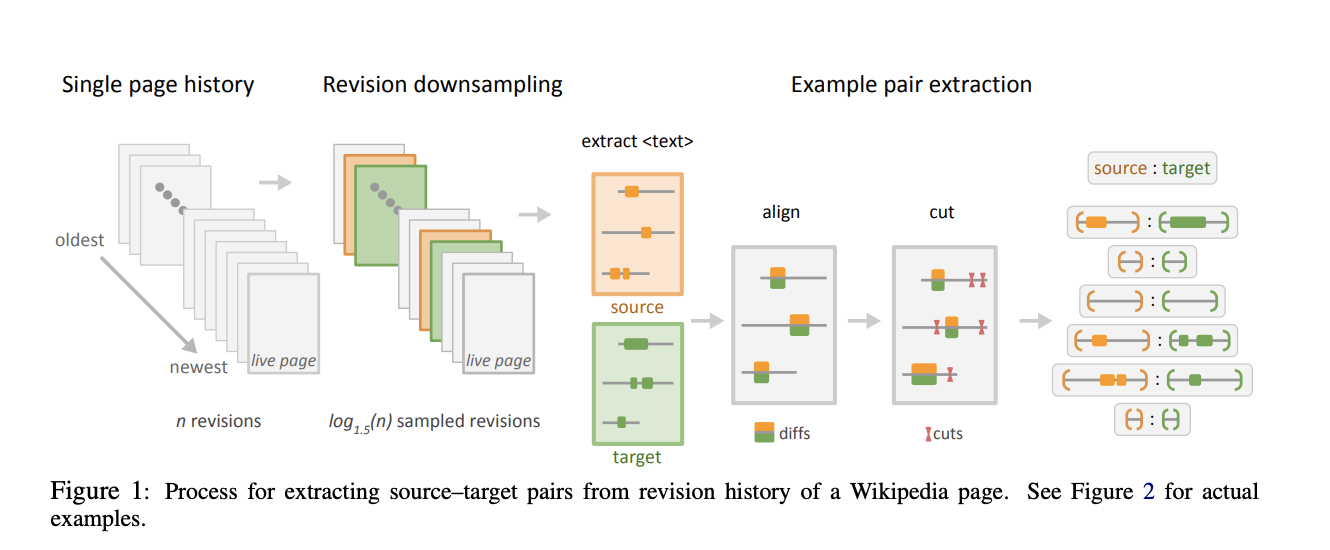
- The majority of examples extracted by this process have identical source and target.
- Since this is not ideal for a GEC parallel corpus, we downsample identity examples by 99% to achieve 3.8% identical examples in the final dataset.
Round-Trip translations
- we extract sentences from the identity examples that were discarded during edit extraction, and generate a separate parallel corpus by introducing noise into those sentences using round-trip translation via a bridge language.
- We use French (Fr), German (De), Japanese (Ja) and Russian (Ru) as bridge languages.
- We randomly corrupt single characters via insertion, deletion, and transposition, each with a probability of 0.005/3.
- Round-trip translations do not contain some types of word and phrase errors (e.g., your/you’re, should of/should have) and so we additionally corrupt the translated text by stochastically introducing common errors identified in Wikipedia.
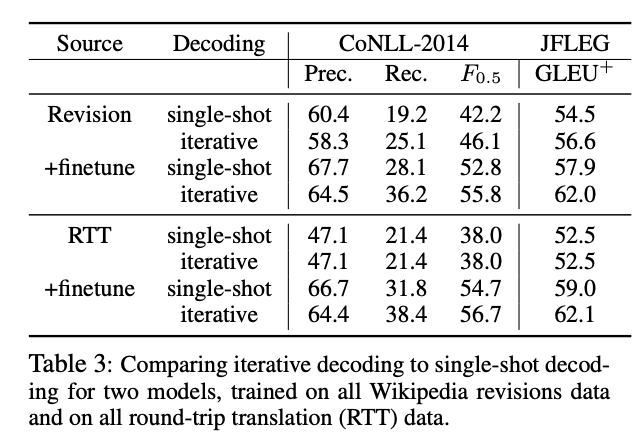
Iterative Decoding
- Read again. Algorithm in Table.
Results

Kaushik Rangadurai
Code. Learn. Explore