Personalizing Grammatical Error Correction: Adaptation to Proficiency Level and L1
Introduction
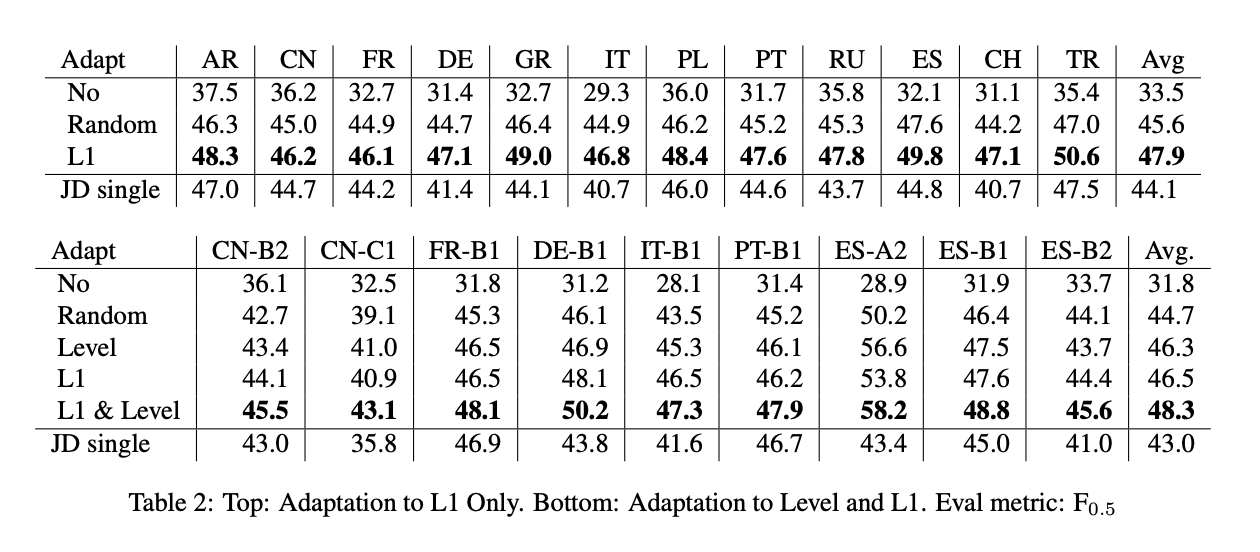
- We present the first results on adapting a general purpose neural GEC system to both the proficiency level and the first language of a writer, using only a few thousand annotated sentences.
- Grammatical errors made by learners are influenced by their native language (L1). For example, Chinese and Russian speakers make more errors involving articles, since these languages do not have articles.
- We believe the future of GEC lies in providing users with feedback that is personalized to their proficiency level and native language (L1).
- We show that a model adapted to both L1 and proficiency level outperforms models adapted to only one of these characteristics.
Architecture
5 proficiency levels - A2, B1, B2, C1, C2. Link 11 L1 languages - Arabic, Chinese, French, German, Greek, Italian, Polish, Portuguese, Russian, Spanish, Swiss-German and Turkish.
Personalizing GEC
- Adaptation of the model to proficiency level and L1 requires a corpus annotated with these features.
- We use the Cambridge Learner Corpus (CLC) (Nicholls, 2003) comprising examination essays written by English learners with six proficiency levels and more than 100 different native languages.
Experimental Setup
- Our baseline neural GEC system is an RNN-based encoder-decoder neural network with attention and LSTM units.
- Use BPE for sub-word tokenization, 20k vocab size and 60 max sequence length with dev set sampled from the train set.
- We create separate datasets for each L1/proficiency level combination where #trainset is 8k, 1k for tuning and 2k for testing.
- Perform standard techniques while fine-tuning on smaller set - dropout, variational dropout of 0.1.
Results

Kaushik Rangadurai
Code. Learn. Explore