Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Introduction
- The goal is to answer natural language queries using code snippets. Think of code snippets in Google Web Answers.
- Query: Open a file “f.txt” in write mode.
- Answer: f=open(‘f.txt’, ‘w’)
Architecture
- Pretraining the model on data extracted automatically from external knowledge resources such as existing API documentation, before fine-tuning it on a small manually curated dataset.
- we implement it on top of a state-of-the-art syntax-based method for code generation, TranX (Yin and Neubig, 2018), with additional hypothesis reranking (Yin and Neubig, 2019).
Mined NL Code Pairs
- Yin et al. (2018) propose training a classifier to decide whether an NL-code pair is valid, resulting in a large but noisy parallel corpus of NL intents and source code snippets.
- The probability assigned by the method can serve as confidence, representing the quality of the automatically mined NL-code pairs. We use these mined pairs as a first source of external knowledge.
Re-sampling API knowledge
- Motivation here is some libraries have extensive documentation (curses for example) but don’t have enough usage (as compared to json for example).
- To mitigate this problem, we propose a retrievalbased re-sampling method to close the gap between the API documentation and the actual NL-code pairs we want to model.
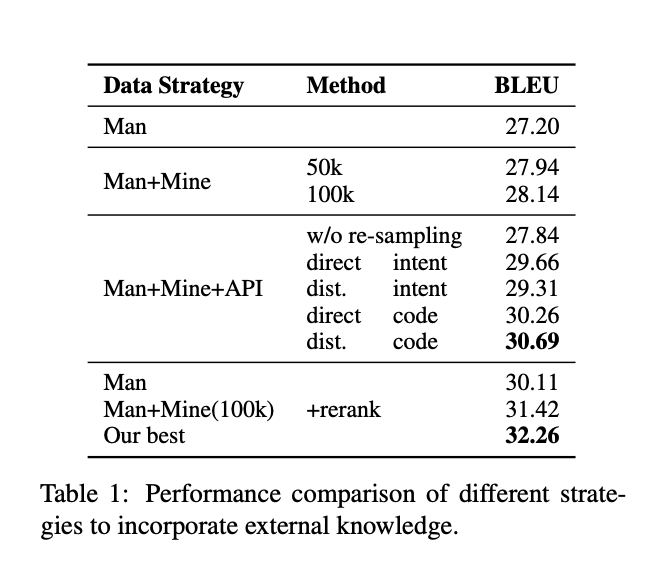
Results
- Using BLEU score on CoNaLa dataset.
- Man is training only on CoNaLa.
- Man + Mined - training on both CoNaLa and mined data.
- API - also use API documentation for training.

Kaushik Rangadurai
Code. Learn. Explore