PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Introduction
- Pre-training objectives tailored for abstractive text summarization have not been explored. We propose pre-training large Transformer-based encoder-decoder models on massive text corpora with a new selfsupervised objective.
- In PEGASUS, important sentences are removed/masked from an input document and are generated together as one output sequence from the remaining sentences, similar to an extractive summary.
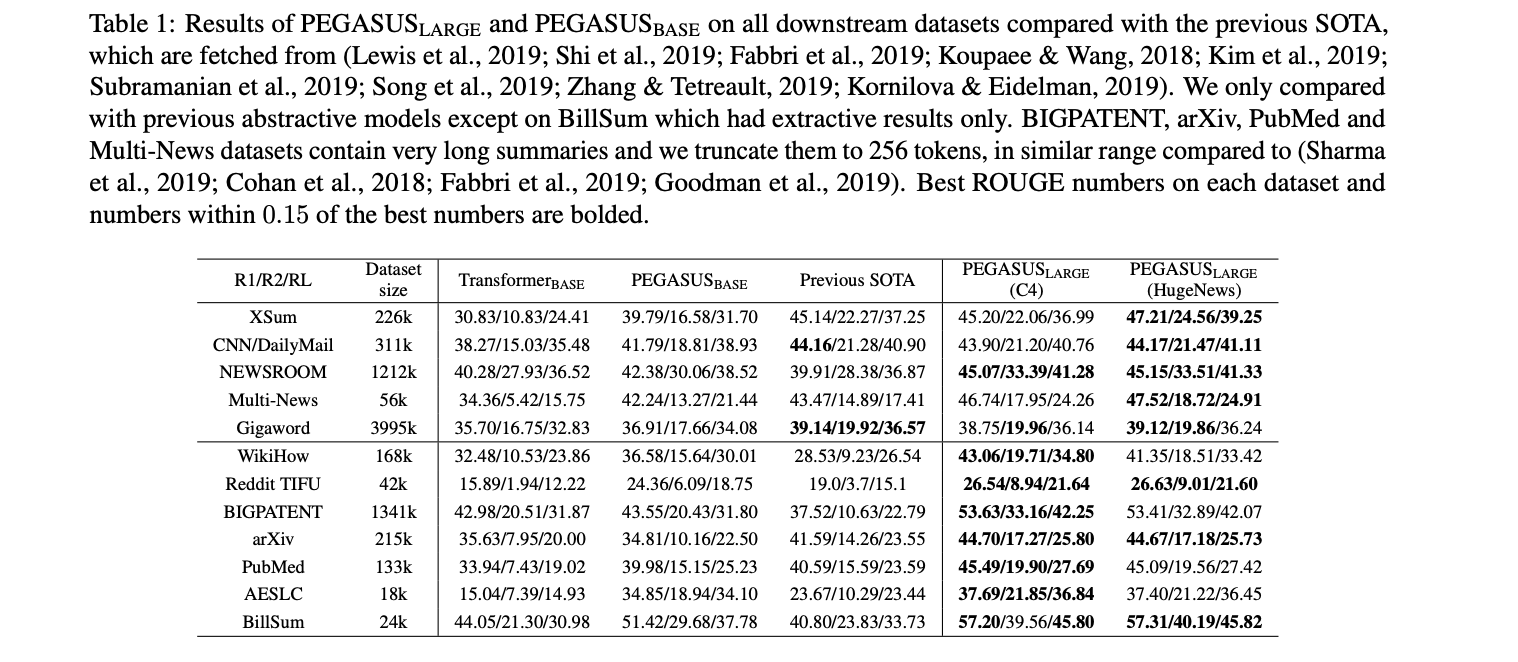
- We evaluated our best PEGASUS model on 12 downstream summarization tasks spanning news, science, stories, instructions, emails, patents, and legislative bills. Achieved SoTA based on ROGUE scores.
Architecture
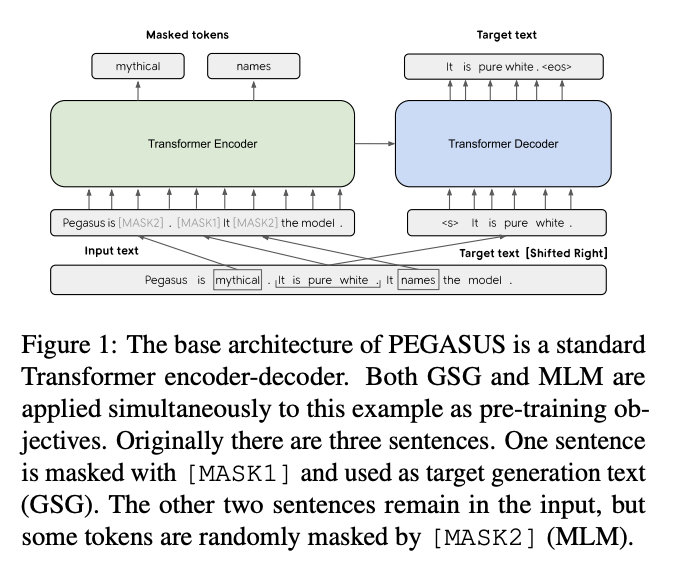
Gap Sentence Generation
-
We find that masking whole sentences from a document and generating these gap-sentences from the rest of the document works well as a pre-training objective for downstream summarization tasks. In particular, choosing putatively important sentences outperforms lead or randomly selected ones.
-
We hypothesize this objective is suitable for abstractive summarization as it closely resembles the downstream task, encouraging whole-document understanding and summary-like generation. We call this self-supervised objective Gap Sentences Generation (GSG).
-
Top sentences are chosen based on Rouge-F1 scores - they can be scored individually (IND) or sequentially (Seq). When calculating ROUGE1-F1, we also consider n-grams as a set (Uniq) instead of double-counting identical n-grams as in the original implementation (Orig).
MLM
- Same as BERT
- However, we found that MLM does not improve downstream tasks at large number of pre-training steps (section 6.1.2), and chose not to include MLM in the final model PEGASUS_LARGE (section 6.2).
Results

Kaushik Rangadurai
Code. Learn. Explore