Embedding-based Retrieval in Facebook Search
Introduction
- Besides the query text, it is important to take into account the searcher’s context to provide relevant results.
- End-to-end optimization of the whole system, including ANN parameter tuning and full-stack optimization.
- For modeling, we propose unified embedding and for fast model iteration, we adopted a recall metric on an offline evaluation set to compare models.
- Investigated 2 directions -
- Hard mining to address the challenge of representing and learning retrieval tasks effectively
- Ensemble embedding to divide the model in multiple stages where each stage has different recall and precision tradeoff.
- Building separate indices and separate retrieval framework -
- Huge performance cost
- High maintenance cost because of dual index
- Two candidate sets might have significant overlap which makes which makes it inefficient overall.
- To solve it, we integrated FAISS into the Inverted index based retrieval.
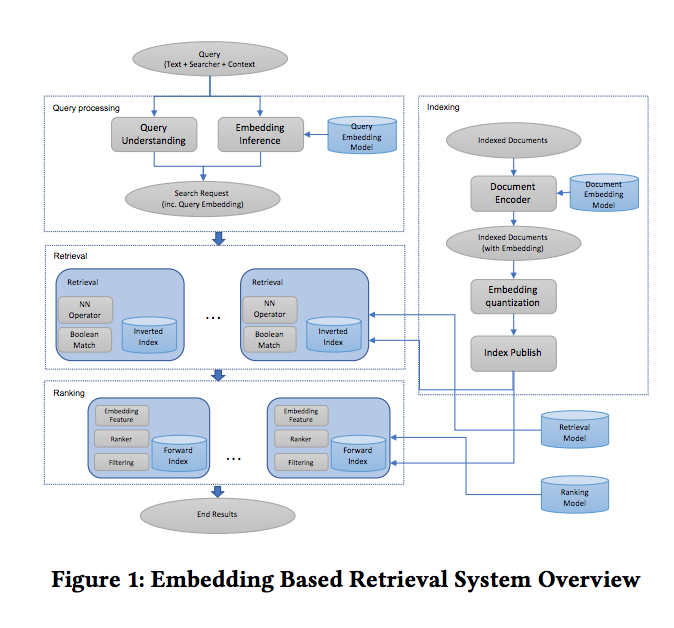
Architecture
Model and Data
- We formulate search retrieval task as a recall optimization problem - number of relevant results / total number of relevant results.
- We use cosine distance and triplet loss.
- Tuning for margin is important and different value of margin values result in 5-10% KNN recall variance.
- Recall@K was used as offline evaluation metric
- Model trained using non-click impressions as negative has significantly worse model recall compared to using random negative.
- Adding impressions as positive did not provide additional value.
- Use click data as positive and random as negative can provide reasonable model performance.
- Unified embedding is more effective than just text embedding.
Features
- Character trigrams (smaller vocab than word n-grams). Good at fuzzy text match and optionalization.
- Location features
- Social Embedding features
Serving
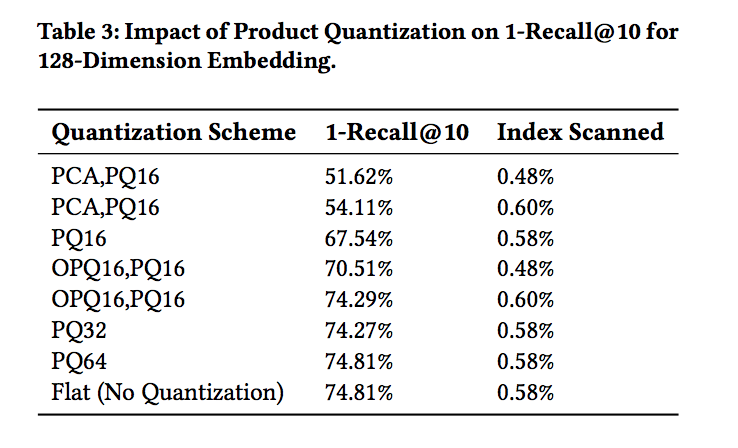
- Quantization - coarse vs product (Read more here!)
Query and Index Selection
- Ignore EBR for certain queries (for eg. direct queries)
- On index side, only use EBR for popular documents.
Later-stage optimization
- Embedding as a ranking feature - Cosine similarity, Hadamard product and raw embeddings. Cosine works best!!
- Training data feedback loop - use raters!
Advanced Topics
- Hard Mining - Online hard negative mining (batch negatives) and offline hard negative mining
- Embedding ensemble - weighted concatenation and cascade model.
Results

Kaushik Rangadurai
Code. Learn. Explore