BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Introduction
- BART: a denoising autoencoder for pretraining sequence-to-sequence models.
- BART is trained by
- corrupting text with an arbitrary noising function, and
- learning a model to reconstruct the original text using a Seq2Seq.
- Can be seen as generalizing BERT (encoder) and GPT (decoder).
Architecture
It is implemented as a sequence-to-sequence model with a bidirectional encoder over corrupted text and a left-to-right autoregressive decoder.
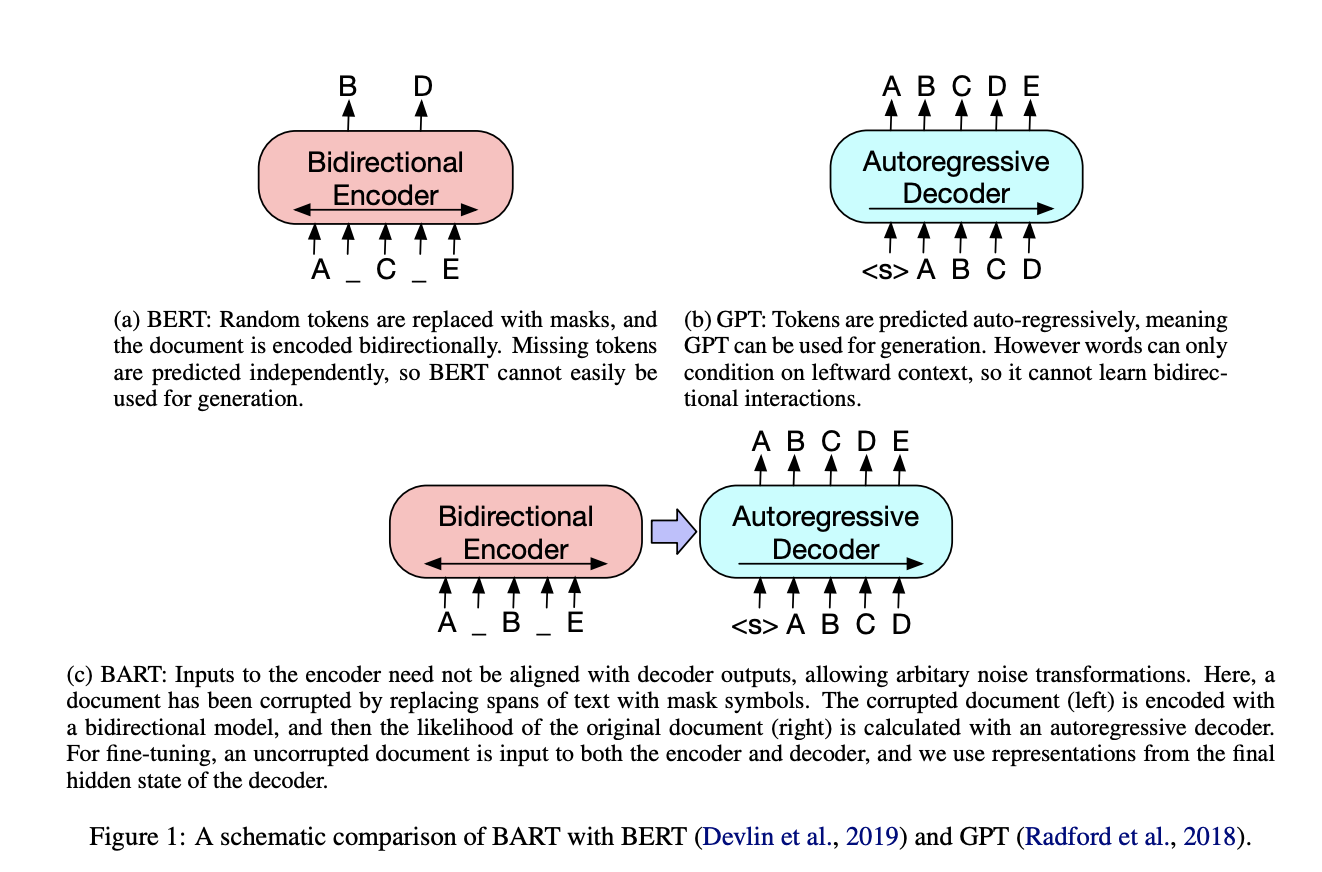
Difference to BERT
- Each layer of the decoder additionally performs cross-attention over the final hidden layer of the encoder (as in the transformer sequence-to-sequence model).
- BERT uses an additional feed-forward network before word prediction, which BART does not.
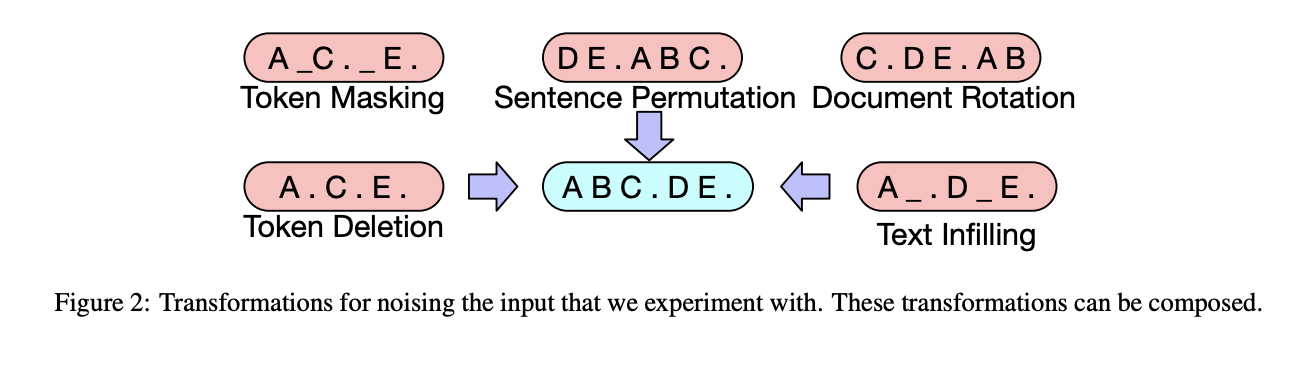
Pre-training BART
Fine-tuning BART
- Sequence Classification - Same input is fed to both encoder and decoder.
- Token Classification - same as sequence classification but token level.
- Sequence Generation - standard encoder decoder.
- Machine Translation - TBR.
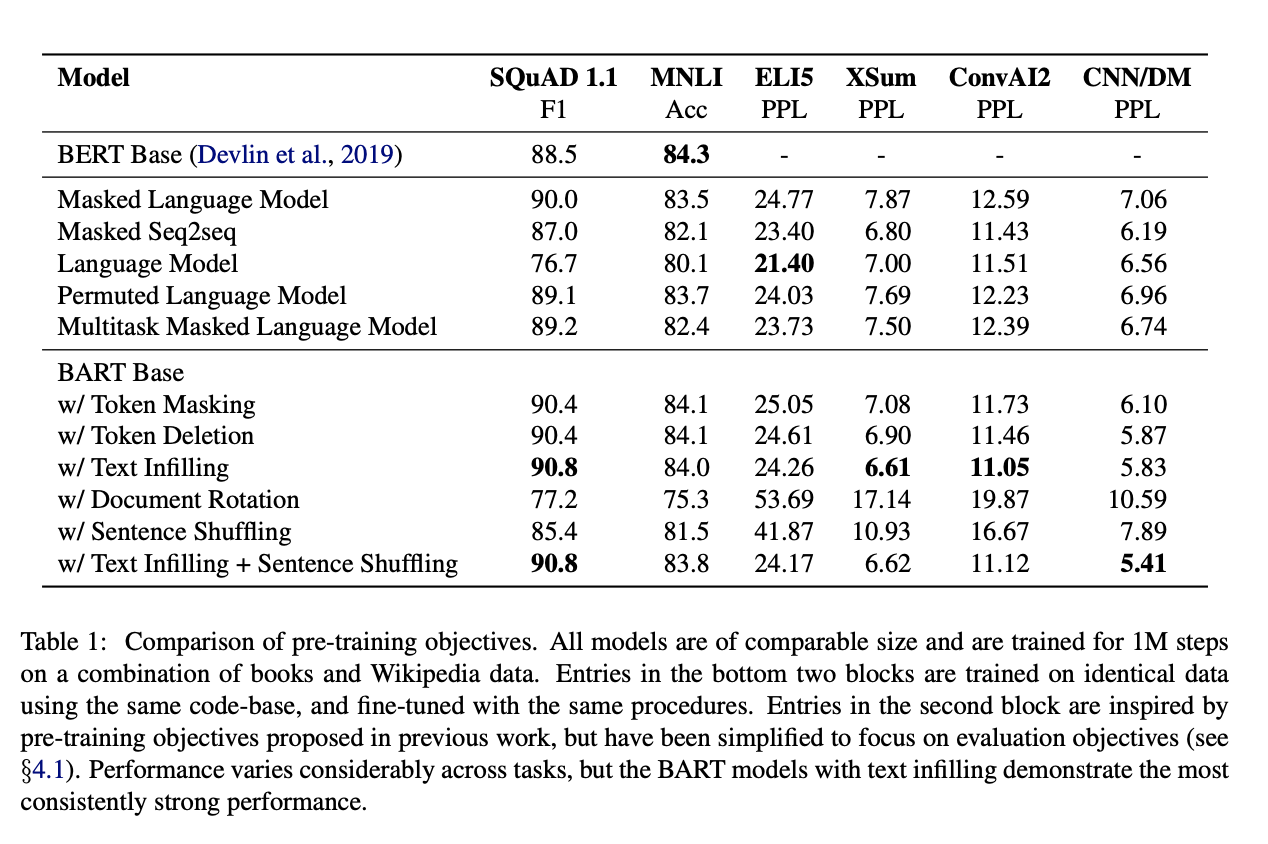
Results

Kaushik Rangadurai
Code. Learn. Explore